
Modern Artificial Intelligence relies on data. As AI solutions become more sophisticated and are applied across different domains, managing datasets efficiently, securely, and sustainably becomes significantly important. This is exactly the challenge addressed by the RAIDO Data Lake, which serves as the central information management layer of the platform.
The RAIDO Data Lake brings together datasets, AI models, monitoring information, workflow artefacts, and analytical outputs generated across all project pilots into a single, unified environment. Rather than maintaining separate storage systems and repositories for different applications, the Data Lake provides a common infrastructure that supports the entire AI lifecycle, from data ingestion and model training to evaluation, optimization, and deployment.
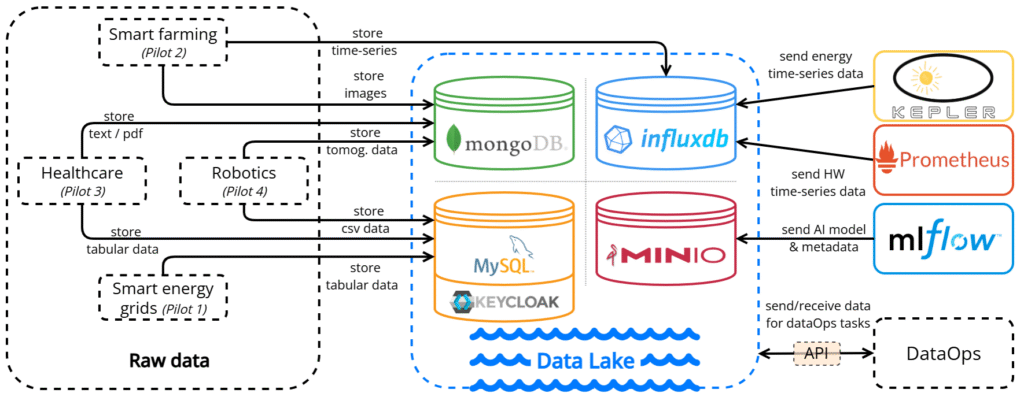
A key requirement of RAIDO is the ability to support highly diverse pilot environments. The project covers smart energy grids, smart farming and fungal food production, healthcare and pharmacogenomics, as well as plant fibre characterization and robotics. Each pilot produces different types of information, ranging from structured measurements and time-series data to medical reports, high-resolution images, simulation outputs, and AI models. The Data Lake has been designed to handle all these data sources while ensuring that information remains accessible, reusable, and securely managed throughout the project.
To achieve this, the Data Lake follows a multi-database approach, using the most appropriate (open source) technology for each type of data. MySQL is used for structured and tabular datasets, MongoDB manages images, documents, and semi-structured information, MinIO stores AI models and large binary artefacts, and InfluxDB supports monitoring and time-series data, including infrastructure (hardware) and energy-consumption metrics. Together, these technologies provide a flexible and scalable storage ecosystem capable of supporting the wide variety of data generated across the RAIDO pilots.
Beyond data storage, the Data Lake plays a crucial role in supporting RAIDO’s vision for trustworthy and green AI. The platform continuously monitors computational resources and energy consumption during AI workflows, enabling researchers to evaluate not only model performance but also their environmental impact. This capability supports evidence-based optimization and contributes to the development of more sustainable AI solutions.
The architecture has also been designed with scalability and interoperability in mind. As datasets grow and AI workflows become more complex, the infrastructure can evolve accordingly, ensuring long-term usability beyond the project’s initial deployment. At the same time, the Data Lake enables seamless collaboration between different RAIDO components, allowing AI services, monitoring tools, visualization modules, and optimization mechanisms to exchange information through a shared environment.
The implementation of the complete Data Lake infrastructure, including the backend services, APIs, deployment environment, and hosting infrastructure, has been led by UBITECH. Through the development of a cloud-native architecture and a comprehensive set of integration services, UBITECH has delivered the foundation that allows all RAIDO components to communicate, exchange data, and operate as a unified platform.
As RAIDO continues to advance reliable, explainable, and resource-efficient AI technologies, the Data Lake remains a cornerstone of the ecosystem. By providing a secure, scalable, and sustainable data foundation, it enables innovation across all pilots while helping transform ambitious AI research into practical, real-world solutions.
Find us on Social Media
![]()
![]()
![]()




